ШТРИХОВОЙ КОД И ЧИСЛО 666Исследование третье.Обитель преподобного Григория Святой Горы. 23 июня 1997 года. Текст в оригинале на греческом языке. После официального опубликования результатов исследования на сайте Св.Горы Афон, сайт был взломан злоумышленниками и информация уничтожена. Текст в оригинале на греческом языке. После официального опубликования результатов исследования на сайте Св.Горы Афон, сайт был взломан злоумышленниками и информация уничтожена.
ПРОЛОГЭта рукопись — плод скрупулезного научного исследования,посвященного связи системы штрихового кодирования (bar code) с числом 666, которую подвергают сомнению некоторые специалисты. После более серьезного рассмотрения этого вопроса мы предложили двум братьям нашей святой обители — иеромонаху о.Луке и монаху о.Продрому (в прошлом — дипломированному программисту) исследовать этот вопрос с научной точки зрения и установить истину, а также выяснить: насколько состоятельны доводы, опровергающие эту связь. Первое исследование завершилось предварительным информационным сообщением о штриховом коде и было послано в обители Святой Горы 29 мая 1997 года. Вторая работа была опубликована 17 июня 1997 года с целью обсудить определенные богословские вопросы, относящиеся к этой многогранной теме и вкратце обнародовать выводы предшествующего исследования. Она была адресована к тем, кто не является специалистом в компьютерной технике. Третье исследование (рукописное) содержит основные элементы предшествующих работ, но в нем более развернуто представлены различные технические вопросы, интересные для профессионалов, что было сочтено необходимым для более полного осведомления большего числа специалистов. Мы надеемся, что эта работа послужит правильному информированию полноты Церкви по вопросу, который, как думают многие из нас, непосредственно связан с исповеданием Господа Иисуса Христа, согласно известному пророчеству Откровения.
Святая Гора, 23 июня 1997 года.
Игумен святой обители преподобного Григория Святой Горы
+ Архимандрит Георгий
Поводом для нашего исследования штрихового когда и его возможной связи с числом 666 явилось письмо от 1 апреля 1997 года от господина Иоанна Кардаса к Священному Киноту Святой Горы. Это письмо выражает широко распространенный взгляд, согласно которому не существует никакой связи между этим числом и штриховым кодом. Мы и сами желали бы, чтобы это было именно так, чтобы наш народ оставался в покое, ибо положение дел в мире и в Греции не так уж и благополучно. Однако мы сожалеем, что наше исследование данного вопроса не дает поводов к самоуспокоению. Наблюдая за развитием событий в Греции и за рубежом, мы разделяем опасения добрых пастырей и верующего народа Церкви по поводу все увеличивающегося отступничества и его сотериологических последствий для народа Божия. Сегодня вопрос о связи штрихового кода с числом 666 приобретает особую серьезность и актуальность. Он непосредственно связан с серьезными проблемами, проистекающими из закона 2472/1997, с новыми электронными удостоверениями и Шенгенским соглашением о границах. Недавнее принятие в греческом парламенте закона "О защите личности от злоупотреблений электронными данными личного характера", перспектива выпуска новых удостоверений личности и ратификация Шенгенского соглашения о границах естественно вызвали беспокойство и противодействие большей части греческого народа. Согласно мнению специалистов, необходимым условием для осуществления Шенгенского соглашения является сбор и электронная обработка сугубо личных сведений на граждан, осуществляемая над-национальными и во многом бесконтрольными органами Европейского Союза (ЕС). И конечно, электронные удостоверения играют ключевую роль при его проведении в жизнь. Явный дефицит демократичности в Соглашении породил обоснованные опасения по поводу нарушения личной свободы. Кто и на основании каких критериев будет истолковывать и оценивать данные личного характера, собранные на граждан ЕС? Следует ожидать, что нарушение личной свободы граждан примет крайние формы, если судьба народов попадет в руки какой-либо тиранической власти. Возможности информатики допускают не только сбор и обработку личных данных на граждан, но и их искажение и отчуждение от компетентных лиц, без каких-либо гарантий защиты этих данных. Опасность нового тоталитаризма очевидна. События последних лет в мире, свидетельствующие о введении "нового порядка" в международных отношениях, являются доказательством возможности установления деспотического режима правления. Несомненно, именно религиозная свобода находится в центре проблемы. Помимо того, что мы лично обязаны бороться с любой тоталитарной системой и ее предтечами, на нас лежит и коллективный долг охранять православный народ от его пленения тайными центрами, которые в будущем будут проводить еще более антихристианские и антиправославные законы по сравнению с теми, которые они устанавливали до сего дня (гражданский брак, безнаказанность блуда, узаконение абортов и т.д.). И может быть, следующей антиправославной мерой в рамках "нового порядка" будет введение общей религиозной веры посредством синкретического, межхристианского и межрелигиозного экуменизма. В мире, изменяющимся таким образом, мы, христиане, не сможем пренебрегать предупреждением о тоталитаризме, о котором пророчествует святой евангелист Иоанн Богослов. В этом предупреждении сказано о невозможности экономического обмена для тех, кто не примет печати, или имени, или числа имени Антихриста (Откр. 13, 16-18). Конечно, целью такой экономической тоталитарной системы является подчинение всех тому, кто поставит себя превыше всякого бога или святыни, чтобы его почитали как Бога (см. 2 Фес. 2, 3-4). Речь идет о вере, о вере либо во Христа, либо в Антихриста. Мы опасаемся, что в подобной перспективе международного и внутреннего положения, глубоко волнующей как религиозных, так и нерелигиозных людей, самоуспокоенность не приведет к добру. Она отрицательно действует на людей и в критическую минуту парализует ответственных лиц. Смешение понятий и самоуспокоенность помешали греческому народу и его духовным вождям последовательно противодействовать принятию парламентом Греции решений, которые бьют по личностной свободе нашего православного народа. Основные положения тех, кто отрицает проблему связи штрихового кода с числом 666, сводятся к следующему: a). Как следует из их изысканий, число 666 не имеет никакой связи со штриховым кодом. b). Постоянное разглагольствование об этой угрозе исходит от протестантских групп и в конечном счете не связано с Православной Церковью и с ее духовной жизнью. Доверие к этой паникерской болтовне удаляет православных от присутствующего в Церкви ожидания Христа, Грядущего во второй раз. g). Мы, православные, воздерживаясь от "эсхатологического синкретизма" (как характеризуется совпадение точки зрения с протестантами в этом вопросе), должны предаться трезвенному деланию, чтобы, ища Антихриста, не потерять Христа. Поскольку тема является действительно серьезной и никто из нас не свободен от ошибок, то с целью более точного осведомления наших православных братьев мы выскажем следующие замечания. 1. Беспокойство православных относительно связи числа 666 со штриховым кодом не имеет протестантского происхождения, но выражает подлинное действие православного чувства. 2. Это беспокойство является свидетельством трезвенного состояния, духовного бодрствования, любви ко Христу и желания спасения.
3. Число 666 явно связано по крайней мере с определенными типами штриховых кодов. В будущем мы достаточно осторожно выскажемся относительно других типов. Беспокойство по поводу 666: здравая реакция православного чувстваПравославных клириков и мирян обвиняют в бесконтрольном усвоении выраженной некоей госпожой Рельфе протестантской точки зрения относительно числа 666 и новой системы расчета посредством электронных карт. Несомненно, в греческих книгах и публикациях по этому вопросу иногда появлялась ошибочная информация из иностранной литературы, как и неадекватная характеристика событий в нашей стране. Осуждение подобных явлений весьма важно. Однако ошибочным является довод о протестантских истоках беспокойства из-за присутствия в штриховом коде символического числа Антихриста. Даже если предположить, что связи штрихового кода с числом Антихриста не существует, мы настаиваем на том, что тревога православного народа по этому поводу исходит не из протестантизма, но является здоровой реакцией православного чувства. Какой православный христианин принял бы в свое личное удостоверение такой символ, зная, что начертание или число Антихриста примут те, кто отрекутся от Христа? И какой свободный гражданин примет тоталитарный режим экономического обмена, зная, что в рамках подобных систем легко провести в жизнь самые гнусные духовные извращения? Разве экономическая блокада не является самым действенным рычагом давления на народы в навязывании им чуждых духовных и культурных начал и законов? Разве чуткость к вопросу исповедания Христа или отречения от Него — не проявление православной доброй совести, равно как и чувствительность к вопросу свободы человеческой личности? Здесь следует подчеркнуть, что православное чувство здраво действует в тех православных, которые удерживают в неприкосновенности догматическое учение Церкви и борются за то, чтобы жить святой жизнью и согласно преданию Церкви. Заметим также, что по мере того, как это служит более полному информированию, мы считаем полезным подробный рассказ о личности и религиозных взглядов всех неправославных, занимающихся этой темой (как, например протестантской писательницы М.Рефле, о которой говорят, что она "соблазнила" греческих писателей). Однако мы не соглашаемся с мнением, согласно которому православные прельстились неправославными идеями и по заблуждению противодействуют введению электронных удостоверений из-за возможной связи с ними числа 666.
Требование элементарной логики состоит в том, чтобы отделить проблему 666 и электронных удостоверений от убеждений какого-то ни было писателя. Православный догматический критерий не позволяет принимать еретические мнения, даже если они касаются важных вопросов. К счастью, православные не имеют Папу, который один определял бы догматы для всей Церкви; но никто из нас не может быть и неподконтрольным "маленьким папой", догматично выражающим свои взгляды. Мы, православные, действуем, как Церковь. Поэтому и более древние толкования числа Антихриста не завершили учения Церкви. Следовательно, сегодня требуется, чтобы снова проявилось самосознание Церкви. Сопротивление православного народа — знак духовного бодрствованияОсновной довод тех, кто отрицает связь числа 666 со штриховым кодом, состоит в том, что нам надо не беспокоиться, но хранить "трезвение", связанное с хранением православной веры и соблюдением Божественных заповедей, чтобы мы, имея таким образом печать Агнца на нашем челе, участвовали и в Его брачной вечери. Можно считать это мнение ошибочным. Трезвение, духовное бодрствование и приготовление действительно являются главной заботой православных христиан, любящих Христа и стремящихся к своему спасению. Но эти существенные добродетели сегодня утеряны многими обмирщенными христианами, богом которых стали деньги, удовольствие, слава. Священное Писание утверждает, что вначале придет отступление, а затем явится "человек греха, сын погибели, противящийся и превозносящийся выше всего, называемого Богом или святынею" (2 Фес. 2, 4), то есть Антихрист. Почти наверняка те, кто поработились вышеназванным страстям, не смогут сопротивляться принятию числа Антихриста и не будут сопротивляться, потому что эти страсти будут толкать людей к принятию этого числа, а оно будет обслуживать эти страсти. Однако верующий православный народ, подвизающийся, чтобы жить по Божьим заповедям, будет сопротивляться соединению его личных данных (например, удостоверения личности) с числом Антихриста или его символом, потому что он предвидит деспотическое введение антихристовых законов и нравов после их принятия. Этот народ твердо держится за неповрежденное догматическое учение Православной Церкви и борется за то, чтобы сохранить его чистым от всякого синкретизма. И более того, этот народ не впадает в "эсхатологический синкретизм" (как называют совпадение точек зрения с неправославными на число 666), ибо синкретизм непременно приводит к догматическому минимализму и к нравственным уступкам, к которым рискуют скатиться все, охотно принимающие символ Антихриста, когда тиранический меч "нового мирового порядка" заставит их воспринять и "мессию", ожидаемого всеми ересями.
Но даже и в том случае, если бы не существовало связи числа 666 с электронными удостоверениями, не следовало бы безрассудно навязывать народу дух самоуспокоенности, хотя бы из уважения к демократическим идеалам граждан и их чувствам, и прежде всего — к ценности боговидной свободы человеческой личности. Число 666 определенно связано с формами штрихового кода. Технический анализСистемы автоматического распознавания (automatic identification systems) являются одним из наиболее впечатляющих достижений современной технологии. С ними становится возможным сбор, кодирование и обработка многих данных на людей и предметы. Штриховая система обозначения (bar code) является одним из способов автоматического распознавания данных в компьютерах. Этой системой обозначения может кодироваться информация на людей, объекты, категории предметов и товары рынка. В рамках технологии штрихового кодирования применяется около 20 различных типов кодировок. Каждый тип соответствует определенным техническим и профессиональным потребностям. Однако преимущественно используемыми сегодня типами являются U.P.C.-A. (Universal Product Code — Универсальный код продуктов) — для Соединенных Штатов и Канады и E.A.N.-13 (European Article Numbering — Европейская система нумерации товаров) — для всего остального мира.
Мы исследовали эти два типа, потому что их подозревают в связи с числом 666, то есть утверждают, что они имеют три штриховых символа, представляющих число 6. Вопрос состоит в следующем: связаны или нет эти символы с числом 6? Зрительная связьФормы этикеток, соответствующих типам E.A.N.-13 и U.P.C.-A показаны на следующей схеме 1.
Штриховые символы в начале, в середине и в конце этикеток, соответствующих этим типам кодирования, называются контрольными или защитными знаками (guard bars). Зрительное впечатление таково, что линейное изображение контрольных знаков, то есть символов При использовании трех контрольных знаков оказывается, что число товара всегда сопровождается тремя шестерками [ 1 ]. Откуда такая настойчивость в использовании данных символов, того острия, которое касается религиозного чувства стольких людей? Действительно, подобный символ технически наиболее пригоден для использования в качестве контрольного знака в данном типе кодирования. Однако это удобство связано лишь с первоначальным замыслом стандарта. Почему для этого символа было выбрано число 6, а не другое число? И почему не предложили другой эскиз, чтобы не требовалось использование именно таких знаков? Из множества других существующих кодировок явствует, что другой эскиз оказывается возможным. На схеме 2 показана этикетка типа "Interleaved 2 of 5":
Этот стандарт разработан без использования указанных спорных символов, связанных с числом 6. Затем, здесь нет среднего контрольного знака, так как на этикетке — сорок чисел. Это значит, что проектировщики стандартов E.A.N.-13 и U.P.C.-A могли бы избежать применения трех защитных знаков, если бы использовали другой чертеж. Они могли бы исправить первоначальный чертеж, пусть даже с какими-то издержками, если бы существовало уважение к чувствам христиан в вопросе о числе 666. Напротив, настойчивость в вопросе все более широкого распростанения типов кодирования E.A.N.-13 и U.P.C.-A делает еще более подозрительным использование вышеупомянутых знаков в этих типах. Зрительной связи трех контрольных символов с числом 6 достаточно для того, чтобы повергнуть в беспокойство любого православного христианина. И греческие специалисты по экономике и профессиональные программисты должны были бы внимательно отнестись к самой чувствительности своих соотечественников к такой связи. К сожалению, этого не произошло.
В нашей стране появляются публикации, отражающие точку зрения как частных лиц, так и официальных кругов, согласно которой при помощи математического анализа будто бы ясно доказывается, что три спорных знака по краям и в центре штрихового кода не являются символами числа 6. Говорят, что это — только зрительное впечатление. Поскольку это мнение неправильно, ниже мы приведем развернутое доказательство того, что и на цифровом, и на электронном уровне (т.е. во внутреннем представлении) тождество контрольных символов с числом 6 является несомненным. Общее описание штрихового кода согласно E.A.N-13/U.P.C.-AВ схеме 3 показана этикетка, построенная по типу кода E.A.N.-13. Поскольку тип E.A.N.-13 является развитием типа U.P.C.-A, общие характеристики, относящиеся к примеру, приведенному на схеме 3, описывают оба типа. Рассмотрение конкретных различий этих типов не составляет цели настоящего исследования и поэтому считается излишним.
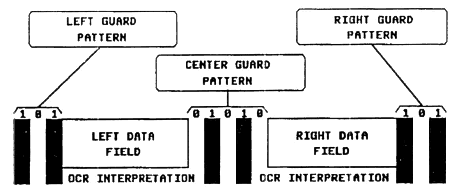
В верхней части кода показано штриховое изображение, а в нижней части — числовое значение штрихов (знаков) этикетки. Первое читается сканером. Второе читается человеческим глазом в том случае, когда сканер не может прочесть код и он должен быть введен в компьютер вручную. Код состоит из последовательности тридцати черных штрихов (линий — bars) и двадцати девяти белых промежутков (spaces) [ 2 ], разделяющихся на две группы, которые называются "левая область" (например, штрихи 449000) и "правая область" (например, штрихи 000996). Области разграничиваются между собой средним контрольным символом (center guard pattern) и замыкаются левым и правым контрольными символами (left and right guard patterns). Это показано на диаграмме (см. схему 4) [ 3 ]. Слева — left и справа — right guard patterns (контрольные символы):
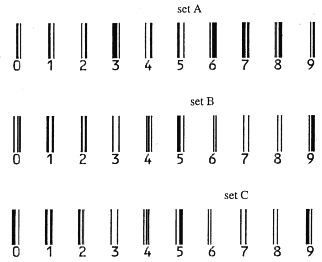
Знаки 0-9 кодируются линейными символами, изображенными на схеме 5. Существуют три группы (set A, set В, set С) знаков, из которых А и В образуют первый уровень (используются в "левой области"), группа С образует второй уровень (используется в "правой области"). Особые контрольные символы в начале, середине и в конце этикетки показаны на схеме 5 [ 4 ].
Цифра 5, которая изображена первой слева на схеме 3, не связана ни с каким линейным символом, но происходит из таблицы I и определяет ряд, из которого берутся знаки группы А и группы В для того, чтобы изобразить шестиразрядное число первого подуровня. В приведенном нами примере (схема 3) знаки первого подуровня будут иметь последовательность А, В, В, А, А, В (см. таблицу I с подчеркнутым числом 5) [ 5 ] .
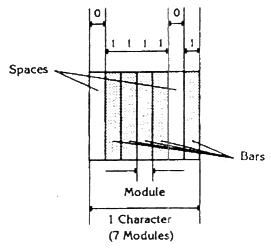
В соответствии с предшествующими образцами, этикетка схемы 3 составлена из следующих знаков:  которые в сжатом виде дают следующую форму:  Определенные технические характеристики устанавливают кодировку согласно E.A.N.-13, к которой полезно вернуться. Код образует симметрию вокруг центрального контрольного знака [ 6 ] и его прочтение сканером проходит в двух направлениях и непрерывно (bidirectional and continuous) [ 7 ]. Каждый знак имеет определенную ширину. Он кодируется двумя черными линиями различной ширины и белым пространством посередине. В знак вносится и другой белый промежуток, чтобы сохранить одинаковую общую ширину [ 8 ]. Ширина черных линий и белых промежутков кратна определенной единичной величине ("модулю") [ 9 ]. На схеме 6 представлено число 3. Оно состоит из белого промежутка в один модуль, черной линии из четырех модулей, белого промежутка в один модуль и черной линии в один модуль. Заметим, что белый промежуток (space) можно сопоставить с цифрой 0, а черную линию (bаг) — с цифрой 1.
Согласно с чертежом кодировки (таблица III), все знаки кодируются 7 модулями; кроме крайних контрольных знаков, которые кодируются тремя модулями, и среднего контрольного знака, который кодируется 5 модулями. 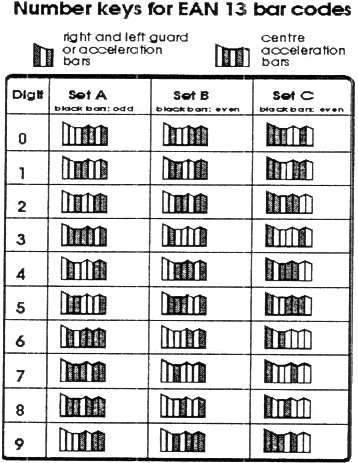
Знаки групп (set) А и В начинаются с 0 (space — промежуток) и кончаются 1 (bar — штрих). Знаки группы С (set C) имеют зеркально противоположную группе А форму: начинаются с 1 и кончаются на 0. Средний контрольный знак справа и слева от единицы имеет белый промежуток (space). Так между штрихами создается пустое пространство по крайней мере в один модуль для разделения между ними, т.е. для того, чтобы была возможна их дешифровка [ 10 ]. Число единиц в знаках группы А является нечетным, 3 или 5 (нечетные соответствия), в то время как число знаков в группе В и С является четным. Компьютер распознает направление прочтения этикетки посредством контроля четности (parity check) [ 11 ].
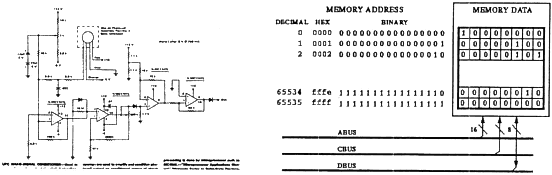
На основании этих и других технических характеристик (см. таблицу IV) становится возможным точная кодировка (encoding) при записи информации с целью последующей правильной и безошибочной дешифровки (decoding) микропроцессором сканера. 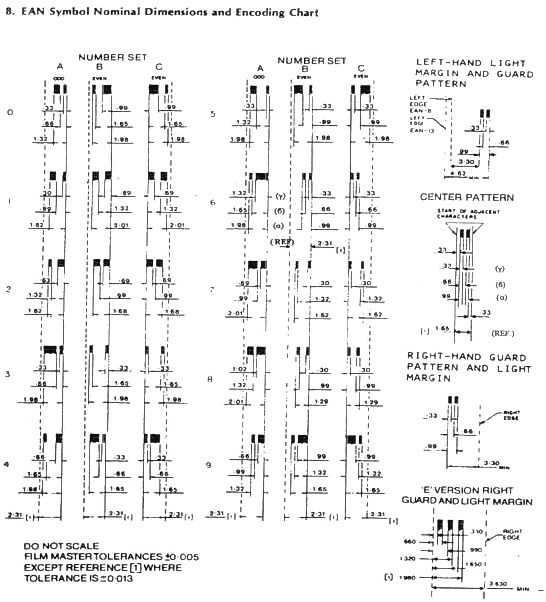 Процедура дешифровки (decoding), то есть извлечения информации, скрытой в этикетке, является достаточно сложным делом. Вмешиваются различные факторы, которые при прочтении создают проблемы. Такие факторы являются следствием несовершенства печати, или изменения скорости чтения во время сканирования, или отражения от этикетки, или угла, под которым сканер читает этикетку [ 12 ].
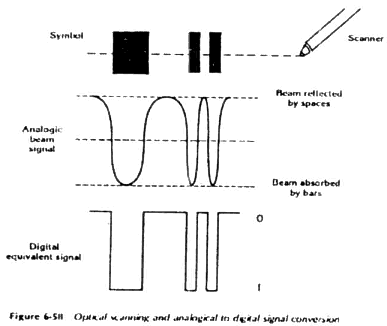
Исследование процедуры декодирования может пролить достаточный свет на изучаемый нами вопрос: является ли сходство контрольных знаков с числом 6 только внешним впечатлением, или они обладают действительным тождеством. Связь на цифровом уровнеПрежде всего, из библиографии, которую мы использовали в этом исследовании, следует, что источником нашей информации является не М.Relfe, но аналитическая техническая информация компаний, научные работы различных институтов и труды профессиональных исследований. М.Relfe не является единственным источником информации о штриховом коде! Кодовое число на какой-либо товар или, например, число ISBN для новой книги дает соответствующая организация, — например, UCC для кодирования U.P.C.-A и ассоциация E.A.N. для кодировки E.A.N. Кодовое число является десятеричным числом (т.е. оно представлено в десятеричной системе счисления). Согласно с приведенной выше таблицей III, десятеричное число превращается в двоичную цифровую последовательность. Компании, печатающие этикетки, на основе технических планов, составленных заранее, печатают этот цифровой код в виде набора распознаваемых линий. Во время прочтения компьютер определяет ширины штрихов и расстояния между ними не в миллиметрах, а в промежутках времени между поступлением электрических импульсов. Характеристики этих импульсов по идее должны были бы соответствовать ширинам линий и промежутков (bars and spaces) (см. схему 7). Однако в действительности этого не происходит, потому что вмешиваются вышеупомянутые факторы, вызывающие так называемое скольжение (drift) [ 13 ] ширины знаков.
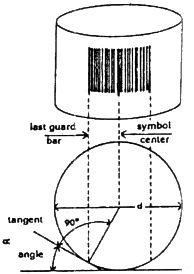
Это скольжение происходит при использовании не только устаревшего wand-сканера, но и современных лазерных сканеров, потому что поверхность, на которой напечатана этикетка, является неровной. Луч прямо падает на одни знаки и под углом — на другие, как показано на схеме 8, где этикетка напечатана на цилиндрической поверхности.
Изменение ширины знаков показано на волнообразной кривой электронного импульса на схеме 10. Мы видим, что пара импульсов, представляющих левый защитный знак (два первых отрицательных импульса слева) различаются по ширине от пары импульса центрального защитного знака (15й и 16й импульс) и от пары импульсов правого защитного знака (29й и 30й штрих), в то время как следовало бы, чтобы они были одинаковыми для удобства прочтения. Следовательно, сканер воспринимает постепенное увеличение ширины знаков справа налево. Поскольку изменение ширины знаков непредсказуемо, то микропроцессор сканера не может распознать очередной знак через полное отождествление его с каким-либо заранее заданным знаком (nominal dimensions, см. таблицу IV). Поэтому он определяет его на основании пропорционального отношения [ 14 ]. На схеме 9 показан штрих-код, специально выполненный по принципу постепенного увеличения ширин знаков до 150% от изначальной, который представляет собой поучительный пример того, как изменение скорости прочтения этикетки (чтение простым сканером, чтение под углом, чтение этикетки, приклеенной на цилиндрическую поверхность и т.д.) в действительности заставляет сканер воспринимать определенные знаки кода как увеличенные или уменьшенные по сравнению с другими знаками того же кода [ 15 ]. В этом смысле ширина единичного модуля не имеет одного и того же временного значения для всех знаков кода. Однако связь единичного модуля определенного знака с шириной этого знака является постоянной для каждого из знаков и равняется 1/7. Сканер (scanteam 5500, Welch Allyn) безошибочно читает код схемы 9 и так показывает аналогичную связь, о которой говорилось выше.
Техника измерения ширин ("width distance")Ниже мы приведем три примера, которые покажут, как микропроцессор сканера сравнивает отношение временных промежутков, чтобы идентифицировать знак. В двух первых примерах декодируется знак 6 и средний контрольный знак при благоприятных условиях прочтения (при образцовом прочтении, т.е. без изменения ширины знаков из-за влияния различных факторов). В третьем примере декодируются крайние контрольные знаки, которые, в случае, если рассматривать только их, дают различные формы импульсов, по причине изменения скорости чтения. Эти формы импульсов могут быть отождествлены, т.е. прочтение этикетки выполнено безошибочно, только на основе вышеупомянутой аналогичной связи временных промежутков, разделяющих знаки. Пример 1. Ассоциация E.A.N. (таблица IV) дает определенный план кодировки. Следовательно, правильное декодирование знака происходит тогда, когда соответствие временных уровней почти совпадает с соответствующими начертаниями знаков в таблице IV [ 16 ]. Предположим, что декодируется серия импульсов, соответствующая знаку 6 (E.A.N.-13, Set В). Сканер анализирует временные длительности импульсов (в миллисекундах), соответствующие ширинам знаков (width distances), которые после декодирования и определяют число 6 (см. схему 11).
Ширины знаков для этого случая:
Компьютер при делении ref/7 = 9.1 мсек/7 вычисляет, что временной эквивалент ширины одного модуля, т.е. единичный временной промежуток (pattern) для знака, о котором идет речь,равен 1,3 миллисекунды. И затем, через деление всех измерений на единичные временные промежутки, компьютер распознает, что: При соотношении длительностей 3:2:1 компьютер распознает двоичное число 101 на основании следующей процедуры. Соотношение 3:2:1 помещается в память разрядностью 8 бит следующим образом: Мa : 00000111 Это может быть выполнено с помощью двух простых команд "Set Carry" (SEC) и "Rotate Left Thru Carry" (ROL) из набора команд (instruction set) микропроцессора МС6800 Motorolla [ 17 ]. Микропроцессор получает и помещает в памяти значение Мх искомого двоичного числа, как Мх = Мa - Мb + Мg = 00000111 - 00000011 + 00000001 = 00000101. (Нули, которые добавляются слева до заполнения восьми битов, не влияют на информацию. Это становится понятным, если регистр микропроцессора состоит из 16 бит, так что Мх = Мa - Мb + Мg = 0000000000000111 - 0000000000000011+0000000000000001 = 0000000000000101). По числу Мх, помещенному в памяти, рассчитывается четность (parity) знака, который в данном случае содержит четное число единиц (even parity) [ 18 ], и в результате на основании таблицы IV определяется символ, соответствующий числу 6 (set В).
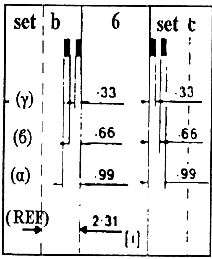
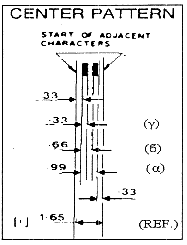
[ Замечание: алгоритм вычисления Мх = Мa - Мb + Мg = 00000111-00000011 +00000001= 00000101 "binary" = Пример 2. С тем же соотношением временных измерений 3:2:1 анализируются и три контрольных знака, потому что и для них при чтении создается серия импульсов, в которой расстояния, описывающие знак, равны, соответственно: 0,99 мм, 0,66 мм, 0,33 мм.
Так, для центрального контрольного знака (center guard pattern, см. схему 12) характерны ширины:
Компьютер через деление ref/5 = 6,5 мсек/5 подсчитывает протяженность единичного временного промежутка (pattern) = 1,3 мсек. Затем, деля все измерения на этот единичный промежуток, он распознает, что: Но это же соотношение 3:2:1 является характерным и для числа 6, что понятно из анализа предыдущего примера. Пример 3. На схеме 10 показана волнистая линия, которая появилась при прочтении этикетки. На ней левый контрольный знак дает намного меньшие длительности импульсов, чем правый. Как же эти два знака будут прочитаны с тем, чтобы продолжилась процедура прочтения и других штрихов? Это происходит через сравнение соотношений временных протяженностей, которые характеризуют оба знака. Так, для левого контрольного знака измеряются следующие временные значения: (ref) = 2,55 мсек; (a) = 2,55 мсек; (b) = 1,75 мсек; (g) = 1,00 мсек. Затем, для правого контрольного знака измеряются временные значения: (ref) = 6,7 мсек; (a) = 6,7 мсек; (b) = 4,3 мсек; (g) = 2,3 мсек. Мы замечаем, что значения для правого контрольного знака более чем на 230% превышают соответствующие значения для левого, хотя закодированы одни и те же штрихи. Однако микропроцессор распознает их как одинаковые, потому что, как было сказано выше, сравнивает отношения временных измерений, определяющих знаки [ 19 ]. Эти отношения, как и в предыдущих примерах, получаются при делении измерений (a), (b), (g) на единичный временной промежуток для каждого знака. Применительно к левому контрольному символу единичный временной промежуток равен: (ref)/3 = 2,55/3 =0,85 мсек. Следовательно, измерения дают: (a) 2,55/0,85 = 3 patterns; (b) 1,75/0,85 = 2,05 patterns; (g) 1,00/0,85 =1,17 patterns. Применительно к правому контрольному знаку: (ref)/3 = 6,7/3 = 2,23 мсек. Следовательно, измерения дают: (a) 6,7/2,23 = 3 patterns, (b) 4,3/2,23 = 1,92 patterns, (g) 2,3/223 = 1,03 patterns.
Из сказанного следует, что если абсолютные измерения для одних и тех же знаков имеют между собой отклонения в 230%, то отклонения относительных величин едва достигают 114%. Техника измерения приращений ("delta distance")В этой методике декодирования сравниваются отношения временных измерений знаков (при специальном способе отсчета временных интервалов) с отношением временных измерений знаков-прототипов. Техника delta distance, которую предлагает компания IBM [ 20 ], разрешает как возникающую проблему скольжения величины знаков, так и проблему размывания краски при печатании этикетки [ 21 ] (см. схемы 13 и 14).
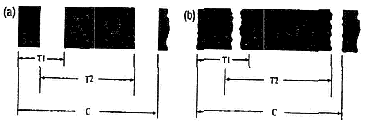
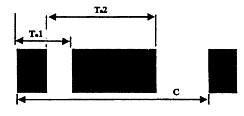
На выбранные таким способом временные интервалы (T-distances) не оказывают влияние изменения штрихов по причине размывания краски [ 22 ]. В частности, в соответствии с данной техникой измеряются следующие расстояния: Т1 — от начала первого штриха до начала второго штриха (от края до края); Т2 — от конца первого штриха до конца второго штриха; С — от начала знака до начала следующего знака.
На схеме 15 показаны прототипы этих расстояний (Т0 - distances) для символа числа 4, Set А. Т01 равняется 2 модулям, а Т02 — 4 модулям.
Таким же образом подсчитываются Т01 и Т02 всех знаков из таблицы II. В приведенной здесь таблице V представлены Т01 и Т02 знаков Set С. Чтобы каждый знак этикетки, читаемый сканером, имел определенные характеристики при дешифровке, необходимо, чтобы измерения Т1 и Т2 были выражены в единицах длительности модуля знака (см. схему 13). Модуль равняется С/7. Следовательно, значение Т1/модуль = Т1/(С/7) будет сравниваться со значением Т01. Подобным образом и значение Т2/модуль = Т2/(С/7) будет сравниваться со значением Т02. Следовательно, можно определить, на сколько процентов эти значения приближаются к значениям Т01 и Т02. Если эти значения окажутся в определенных допустимых пределах отклонения (tolerance) [ 24 ], то знак распознается, как соответствующий прототипу.
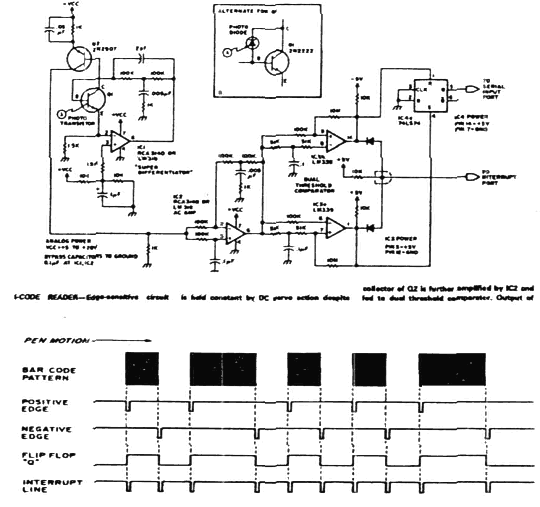
Из описанной техники delta-distance следует, что три контрольных знака имеют одинаковые временные интервалы (T-distances) с числом 6. Достойно внимания то, что если для знаков 1, 7 и 2, 8, имеющих одни и те же значения T-distances, требуется дополнительная операция по непосредственному измерению ширины штрихов с привлечением вышеописанной техники width distance для их различения между собой (см. примечание [ 23 ]), то для контрольных знаков, имеющих значения T-distances, одинаковые со знаком 6, не требуется их дифференциация от знака 6 (как это следует из литературы). Совершенно очевидно, что они отождествляются с числом 6. Связь на электронном уровнеВ предыдущей главе мы показали, что как в технике измерения width distance, как и в технике измерения delta-distance, контрольные знаки отождествляются с числом 6. Далее мы покажем, как микропроцессор сканера применяет эти методики на электронном уровне. В процедуре прочтения этикетки (декодировании) каждый черный штрих дает отрицательный импульс (затененная область в серии импульсов на схеме 10), а каждый белый промежуток дает положительный импульс. Эти импульсы преобразуются в импульсы переменной ширины (pulse width modulation). Что это значит? Это означает, что читающее устройство (сканер) посылает в компьютер электромагнитные волны временной протяженности, соответствующей ширине черных штрихов и белых промежутков на этикетке. Сканер выделяет фронт каждого импульса и начинает процесс измерения, относящийся к этому (определенному) импульсу. При расшифровке серии импульсов компьютер анализирует временные параметры каждого импульса и распознает число, закодированное на этикетке. Эта процедура включает в себя следующие шаги [ 25 ]:
Одна из электронных схем, используемых для прочтения штрих-кодов, имеет вид, показанный на схеме 16.
В процессе чтения этикетки временные интервалы между импульсами, соответствующими положительному перепаду (positive edge) и отрицательному перепаду (negative edge) фиксируются с помощью схемы прерывания, измеряются методом отсчетов (sampling) и помещаются в память компьютера [ 26 ]. По сохраненным в памяти значениям вычисляются времена T1, T2, и С для того, чтобы методом delta distance распознать числа 0, 3, 4, 5, 6, 9 и защитные знаки (guard bars). Затем применяется и метод width distance, чтобы его с помощью выделить числа 1, 2, 7 и 8 [ 27 ].
На примере штрих-кода Цифровая двоичная форма кода выглядит следующим образом:  Без разделительных линий и без нулей (quiet zones) код приобретает следующий вид:
В процессе чтения кода сканер посылает в микропроцессор серию импульсов, изображенных на схеме 17.
Кстати, заметим, что на схеме 17 (импульсы 15й и 16й) показаны два промежутка (spaces) — направо и налево от 101 — центрального контрольного знака (center guard pattern), которые приводят к некоторому кажущемуся отличию изображения этого знака от изображений левых и правых контрольных знаков (left и right guard patterns). Это сделано потому, что при печати этикетки нужно не допустить слияния символов, предшествующих и следующих за центральным контрольным знаком, с ним самим, иначе они создадут совершенно иную связь линий и расстояний, соответствующую другим числам, а не тем, которые должны быть отпечатаны на этикетке. Из измерений ширин (width-distance) и временных интервалов (T-distances) этих импульсов и расшифровки появятся искомые знаки, которые будут занесены в память. Восьмибитовый микропроцессор (например, МС6800 на схеме 18) отправляет в память расшифрованные знаки в следующем виде: Left Guard Pattern = 00000101, 3=00111101, 6=00000101 .... Center Pattern = 00001010, Right Guard Pattern =00000101.
Занесение в память этих знаков в такой форме необходимо, поскольку следует определить "четность" (parities), т.е. четное или нечетное количество единиц, для всех знаков [ 28 ]. В данном конкретном примере знак 3 дает нечетное соответствие (odd parity), а знак 6 — четное соответствие (even parity).
Заметим, что и внутри памяти компьютера видно тождество между тремя контрольными знаками и числом 6, как явствует из приведенных двоичных представлений этих знаков. Три одинаковых контрольных знака не являются необходимымиНесмотря на стихийное выражение чувств простого верующего народа и мнение специалистов о том, что в штрих-кодах типа E.A.N.-13 и U.P.C.-А контрольные знаки явно отождествляются с числом 6,известны попытки подыскать оправдания для определенных фактов, подтверждающих зрительное впечатление о существовании этой связи. Эти факты заключаются в увеличении к низу длины контрольных знаков по сравнению с другими штрихами этикетки, в их сходстве и в симметричности этикетки по отношению к центральной оси. Поскольку упомянутые доводы и оправдания нас не убеждают, то мы лишь вкратце изложим их. 1. Является ли необходимым средний контрольный знак?
a). Существует точка зрения, согласно которой средний контрольный знак является незаменимым, поскольку он также обеспечивает возможность обратного прочтения символа (справа налево):  Однако, если мы рассмотрим код UPC-E, то убедимся, что в нем нет среднего контрольного знака:  Тем не менее, он читается и наоборот [ 29 ]. Следовательно, предшествующий довод не является верным. Однако все известные кодировки, приводимые ниже, содержат более шести знаков, но в отличие от E.A.N. и U.P.C. не имеют среднего контрольного знака: BCD MATRIX, 11 MATRIX, 2/5 COMPRESSED, CODABAR, CODE 39, CODE93, CODE 128, MSI, PLESSEY, DELTA DISTANCE [ 30 ]. Характерный пример показан на схеме 2 (см. выше).
В коде E.A.N.-13 только один десятичный знак может присутствовать вне области штрих-кода, т.е. не иметь соответствия с линейным изображением (например, цифра 5), потому что на основе таблицы I максимальное количество возможных комбинаций групп Set А и Set В в "левой области" равняется 25 = 32, что означает, что из этих комбинаций может возникнуть только одно десятеричное число (first flag character) [ 31 ]. Таким образом, то же число для кода Test могло бы быть изображено так:  2. Крайние контрольные знаки не обязательно должны быть одинаковы и симметричны друг с другом
В научной мысли существует правило, согласно которому всегда избирается более простое решение. Сходство крайних контрольных знаков не только не является необходимым, но является недостатком. Их несходство облегчило бы компьютеру определение направления чтения этикетки при использовании противоположных знаков для обратного прочтения. В данном же случае, когда крайние контрольные знаки подобны и симметричны (E.A.N.-13 и U.P.C.-A.), приходится при помощи специальной программы определять направление чтения, используя контроль четности (parity) первого (не-контрольного) знака. Это означает не упрощение, а усложнение. Парадокс состоит в том, что в E.A.N.-13 и U.P.C.-А., несмотря на сложность, была введена именно эта система одинаковых и симметричных контрольных знаков. Сам этот факт вызывает подозрения относительно намерений программистов. Кроме того, все другие известные типы кодировок имеют крайние контрольные знаки, различающиеся между собой [ 32 ]. 3. Увеличенный размер трех контрольных знаков не является необходимым
Утверждают, что три контрольных знака в кодах E.A.N.-13 и U.P.C.-А. выступают из общего ряда, потому что так уменьшается вероятность ошибок в прочтении сканером-ручкой
Конечно, можно было бы согласиться, что уменьшается вероятность ошибки в чтении (точнее — вероятность непрочтения), когда крайние контрольные знаки имеют больший размер, поскольку известно, что рука совершает движение по кривой, а не по прямой. В коде U.P.C.-A действительно уменьшается вероятность ошибки, поскольку из ряда выступают также знаки 1й и 12й. Однако увеличение длины среднего знака в этом случае не приносит никакой пользы. Итак, по какой причине увеличен средний контрольный знак? В коде же E.A.N.-13 штрихи знаков 1го и 12 го не выходят из общего ряда. Это значит, что польза от увеличения крайних контрольных знаков минимальна (см. схему выше). Возникают вопросы: a) Насколько уменьшается вероятность ошибки при увеличении среднего контрольного знака? b) Если цель этого увеличения — повышение надежности чтения на краях, то почему не запланировано увеличение первого и последнего знаков в коде E.A.N.-13, если оно уменьшает вероятность ошибки (см. пример U.P.C.-А)?
Разве штрихи увеличиваются не для того, чтобы подчеркнуть число 6, чего нет в десятках других кодов, где отсутствуют увеличенные контрольные знаки? ВЫВОДЫС помощью исследований материалов, приведенных в иностранной литературе, и погружения в логику штрихового кодирования (bar-coding) мы попытались раскрыть проблему связи штрих-кода с числом 666. Нашим искренним желанием было прояснить истину в этом спорном вопросе, который в наши дни приобретает особую серьезность. Мы хотели бы, чтобы между штрих-кодом и числом 666 не существовало никакой связи. К сожалению, наше исследование показало, что существует не только связь, но и тождество между определенными типами штриховой кодировки и числом 666. Человеческий взгляд получает зрительное впечатление, согласно которому две тонкие линии в начале, в середине и в конце числа, закодированного по типу E.A.N.-13 и U.P.C.-A, представляют собой изображения числа 6. Это впечатление не обманчиво. То же самое, что видит человеческий глаз, распознает и компьютер. Три контрольных знака (guard patterns) штрихового кода E.A.N.-13 и U.P.C.-A являются выражением чисел 6,6,6, ибо компьютер расшифровывает и распознает контрольные знаки только после того, как сравнивает их с числом 6. В памяти компьютера как число 6, так и контрольные знаки имеют один и тот же цифровой образ — 00000101, несмотря на "различную" двойственную форму, которую они, казалось бы, должны иметь при кодировке (101, 01010, 0000101). Самый злободневный вопрос — почему при разработке стандарта контрольному символу было придано сходство именно с числом 6, а не с другим — от 0 до 9. В нашей работе мы рассмотрели доводы тех, кто сомневается в связи контрольных символов с числом 6 в кодах E.A.N.-13 и U.P.C.-А. Мы ответили на самые главные из них, ибо мы видели, что они не могут скрыть эту связь, которая случайно или намеренно была заложена в изначальную схему этих типов кодировки. Дополнительным доказательством этого являются более поздние типы кодировки, которые не имеют трех контрольных знаков. В наши дни проблема связи штрих-кода с числом 666 стала еще более острой из-за перспективы выпуска новых (электронных) удостоверений личности, вследствие вступления в Шенгенские соглашения. Высказывалось опасение, что электронные удостоверения, помимо информации, нарушающей неприкосновенность частной жизни и личной свободы, будут содержать и число 666. Одно только использование электронных удостоверений очень опасно для свободы человеческой личности, по причине чудовищных возможностей информационных технологий. Даже в том случае, если в удостоверениях нет числа 666, их введение означает для нас продвижение к всемирной тоталитарной системе, которая рассматривает человека не как образ Божий, но как "субъект данных" (закон 2472/1997), который вскоре может стать объектом в руках экономической олигархии, или самого Антихриста. Однако их использование будет просто омерзительным, если каким-то образом оно будет связано с числом 666. Никакой христианин, признающий и почитающий свидетельство святого Иоанна Богослова в Откровении, не сможет принять удостоверение, имеющее символ Антихриста. Многие отрицают эту связь, равно как и очевидный символизм трех чисел 6 — символа, упомянутого в Апокалипсисе. Однако это отрицание не обосновано. Не только самого факта, но и простого подозрения в том, что символ 666 вводится в какой-то предмет, имеющий отношение к человеческой личности, достаточно для того, чтобы побудить христиан немедленно и энергично сопротивляться употреблению этого предмета (например — электронного удостоверения). Такое энергичное сопротивление необходимо, потому что принятие числа Антихриста означает отречение от Христа и сочетание с дьяволом. Это ясно видно из учения Апокалипсиса (14, 9-11), но также — из опыта Церкви со времен святых мучеников. Святые мученики не только не отреклись от Христа словом, но даже не совершали никаких символических действий, связанных с идолопоклонством, потому что это означало для них отречение от Христа. Хотя было сделано заявление, что в новых удостоверениях не будет использоваться штриховой код типа E.A.N.-13 и U.P.C.-A., тем не менее в этом нет никакой уверенности. Помимо этого, экономический тоталитаризм, насаждаемый во всем мире экономической олигархией, непосредственно связан со штриховым кодом, так что вполне вероятно, что исполнится слово Апокалипсиса о невозможности экономического обмена для тех, кто не будет иметь электронного доступа к введенной системе обмена. Процесс объединения Европы составляет быструю череду конкретных мер и действий на техническом, экономическом и законодательном уровнях, основная цель которых состоит в том, чтобы уничтожить все национальные и государственные препятствия и создать единое европейское пространство рынка, сотрудничества и контроля (Гельмут Коль, журнал "Исследования", т.17, с.88).
Следовательно, своевременное и обязательное извещение народа в настоящее время является первым шагом к осознанию ответственности за последствия решений, касающихся такого важного вопроса, как наша вера и личная свобода. Copyright © Свято-Преображенский Валаамский ставропигиальный монастырь, 2000.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





 мы объясним сказанное выше.
мы объясним сказанное выше.